
Bonjour à tous, élèves de 2nd F,
Voici la suite du cours de SNT : nous abordons le chapitre "Des données".
Voici la suite du cours de SNT : nous abordons le chapitre "Des données".
1) Les données : Introduction :
Jeudi 29 Avril 2021
->à rendre avant Lundi 3 Mai 2021
Jeudi 29 Avril 2021
->à rendre avant Lundi 3 Mai 2021

Historique des Données :
Etudiez l'article dans ce lien, et répondez aux questions 1 à 4 du DM.
Etudiez cette image dans ce lien, et répondez aux questions 5 à 9 du DM.
Notions de Données :
Voici, ci-dessous, la vidéo qui nous initie aux notions de "données" ; Répondez aux questions 10 à 17 du DM sur cette vidéo :
Etudiez l'article dans ce lien, et répondez aux questions 1 à 4 du DM.
Etudiez cette image dans ce lien, et répondez aux questions 5 à 9 du DM.
{kind=link}
Notions de Données :
Voici, ci-dessous, la vidéo qui nous initie aux notions de "données" ; Répondez aux questions 10 à 17 du DM sur cette vidéo :
Votre Travail : Vous devez m'envoyer le DM terminé. (Avant le lundi 3 Mai ).
2) Les données : Etude d'un fichier .csv :
Lundi ____
--> à rendre avant Lundi ____
Lundi ____
--> à rendre avant Lundi ____

Répondez aux questions de ce cours dans le DM que vous trouverez en cliquant sur ce Lien .
Problématique de la séance suivante : Quels sont les formats des Données ? Où peut-on s’en procurer ?
I. Différents formats de données :
• Ouvrir chrome (ou tout autre navigateur) ; rechercher : ‘SNCF Open Data’ ; (cliquez sur ‘Explore _ SNCF Open Data’)
• Dans la barre de recherche nommée « filtres » (à gauche) : écrire : ‘gare région’ --> Entrée
• Au centre de l’écran se trouve tous les groupes de données correspondant à notre recherche ;
• Repérez le groupe nommé ‘Référentiel des gares de voyageurs’ ;
* --> Cliquez-droit (nouvel onglet) dans ce référentiel sur ‘Tableau’ :
--> Combien de colonnes contient ce tableau ? :
--> Combien de lignes contient ce tableau ? :
* --> Dans les onglets « ‘informations’, ‘tableau’… » cliquez sur l’onglet ‘Export’ ;
* Cliquez sur ‘J’accepte les conditions…’
* Nommez les différents formats de fichiers ‘plats’ :
--> Cherchez une définition courte du format CSV :
--> Cherchez une définition courte du format JSON :
* Nommez un format de fichier géographique ressemblant à un des formats précédents :
A. Le format CSV :
* --> Dans l’onglet ‘Export’, cliquez sur le lien ‘CSV Jeu de données entier’
--> le document se télécharge à votre écran ; Faîtes un clic-droit sur le document téléchargé, et cliquez sur ‘Afficher dans le dossier’ ;
• Récupérez/glissez le fichier ‘referentiel-gares-voyageurs.csv’ dans un dossier de votre ordinateur de votre choix (par exemple : SNT/Données) ;
* --> Faîtes un clic-droit sur le fichier ‘referentiel-gares-voyageurs.csv’ et choisir : ‘ouvrir avec’ : Choisissez l’application Word (Ne cochez pas la case ‘toujours utiliser cette application') ;
--> Dans la petite pré-fenêtre qui s’ouvre, laissez Unicode UTF-8 et faîtes OK.
--> Combien de mots contient ce fichier ? : : Ce sont des données !
--> Faîtes un Ctrl A, et imposez la police ‘Times New Roman _ 6 ’ et faîtes un zoom à 170% ;
--> Repérez la 1ère ligne : Que contient-elle (vu au 1er chapitre) ? :
--> Par quoi semblent séparées les différentes données pour chaque ligne ? :
Assurément, un logiciel de traitement de texte n’est pas le meilleur outil pour des données tabulaires…
--> Fermer Word sans enregistrer ;
* --> Ouvrez Excel ; Cliquer sur Fichier-->Nouveau-->Nouveau Classeur ;
* --> Cliquez, dans la barre d’outils sur ‘Données’ ;
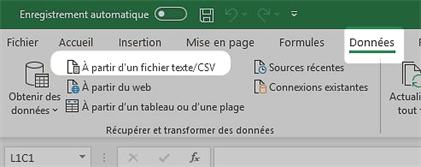
* -->Puis, cliquez sur ‘A partir d’un fichier texte/CSV’ ; repérez le fichier ‘referentiel-gares-voyageurs.csv’ et importez-le ;
-->Une fenêtre aperçu s’ouvre nous montrant le résultat du traitement par Excel si nous prenons comme délimiteur de données le symbole : _ _ _ _ _ _ _ _ _
-->Si on utilise le délimiteur ‘virgule’, on obtient _ _ colonnes, et certaines données sont _ _ _ _ _ _ _ _ avec d’autres (donc pas intéressant !) ;
-->Si on utilise le délimiteur ‘espace’, qu’observez-vous ? :
* -->Re-séléctionnez le délimiteur le mieux adapté :
* Certains mots sont mal écrits, on a perdu les _ _ _ _ _
--> Dans le menu déroulant ‘Origine du fichier’, choisir, tout en bas : 65001 unicode (UTF-8) : l’UTF-8 permet de gérer les accents
* Et cliquez sur ‘Charger’.
--> Le tableau se charge. Regardez à droite, combien de ligne de données contient ce tableau ? :
• Que remarquez-vous au niveau de la présentation des descripteurs en ligne 1 ? :
* -->Cliquer sur le triangle du descripteur en colonne 2 nommé : ‘intitulé de gare’, et écrire dans la barre de recherche du menu déroulant qui s’affiche : « Reims »-->Entrée ; Qu’observez-vous ? :
* --> Cliquer sur l’entonnoir du même descripteur, et dans le menu déroulant, cliquer sur ‘effacer le filtre’ ;
--> Déplacez le tableau en colonne 15, et demandez les données correspondant au département de la Marne (51) : vous observez _ _ gares trouvées. (chiffre vu en bas à gauche de votre écran)
• Sans revenir en arrière, passez en colonne 22, cliquez sur le triangle du descripteur ‘niveau de service’ et décochez le chiffre 1, puis faîtes ‘ok’ ; qu’observez-vous ? :
-->Ainsi, avec Excel, on peut croiser des requêtes sur des données en agissant sur le tri des descripteurs.
Cherchez ce qu’est une requête.
Fermez Excel (pas besoin d’enregistrer).
Avec Python, nous allons pouvoir travailler les Données plus librement.
--> Récupérez le fichier Juyter nommé ‘4_2_1 CSV_Jupyter.ipynb’, et placez le dans un dossier (par exemple : SNT/Donnees) ;
--> Récupérez le fichier nommé ‘villes_virgule.csv’, et placez le dans le même dossier pour que le programme le trouve ;
--> Dans un premier temps, faîtes un clic-droit sur le fichier nommé ‘villes_virgule.csv’, et choisissez ‘Ouvrir avec’, puis choisissez l’application Word (ne pas cocher la case : toujours avec cette application !) ;
--> Faîtes en sorte que le fichier s’ouvre en Unicode (UTF-8)
* Quel est le délimiteur de données ? :
* Le nombre de page est de : _ _ _ ; le nombre de mots est de : _ _ _ _ _ ;
--> C’est bien de la Data (Fermez Word sans enregistrer)
--> Ouvrir EduPython, puis le serveur Jupyter en prenant SNT/Donnees comme répertoire de base
--> Ouvrez alors, dans Jupyter, le fichier ‘4_2_1 CSV_Jupyter.ipynb’;
--> Commençons par étudier la 1ère cellule de code nommée ‘Script 1’ :
--> Dans ce programme, quelle est la commande pour :
• récupérer le module ‘pandas’ : _ _ _ _
• lire un fichier de format .csv : _ _ _ _ _
--> Dans quelle variable le contenu du fichier csv est placé ? : _ _ _ _
--> Quelle est la commande pour visualiser le contenu d’une variable : _ _ _ _
--> A présent, lançons le script 1 (barre bleue à gauche du code !) : cliquez sur Exécuter (bouton Play :45sec. d’attente..) ;
-->Combien de lignes et de colonnes contient ce tableau de données ? :
--> Dans le tableau affiché sous le script1, qu’observez-vous ? :
--> Lorsqu’il y a trop de données à afficher, Python crée des raccourcis pour ne pas encombrer la cellule de résultats.
* Exécutez le script nommé ‘Script 2’ : Qu’observez-vous comme résultats ? :
* Qu’en déduisez-vous ? :
--> Exécutez à présent le script nommé ‘Script 3’ ;
* Ecrire ‘paris’, puis ‘Paris’ ; qu’observez-vous ? :
* A présent, demandez une ville de votre choix ;
J’ai choisi la ville de : _ _ _ _ _ _ _ ; surface = _ _ _ km² ; Altitude_max=_ _ _ mètres.
* Faîtes ‘ q ‘ pour quitter.
--> Exécutez à présent le script nommé ‘Script 4’ permettant de réaliser une requête sur l’altitude :
* Ecrire l’altitude 1600 -->Entrée ; J’observe _ _ _ villes ayant cette altitude minimale.
* Copiez la ville qui a l’altitude la plus élevée ; Stoppez le script 4 (écrire 0 -->Entrée), remettez à zéro les cellules (dans la barre de menu) (Kernel-->Restart & clear Output-->Restart & clear all outputs), puis Exécutez (Bouton Play) le script 3 en collant (Ctrl V) la ville la plus élevée :
--> Donnez son code postal : _ _ _
--> Son nombre d’habitant en 2012 : __ _ _ _
--> Sa surface : _ _ _ _
Ainsi, Python et son module pandas sont parfaitement adapté pour analyser des données.
-->Une fenêtre aperçu s’ouvre nous montrant le résultat du traitement par Excel si nous prenons comme délimiteur de données le symbole : _ _ _ _ _ _ _ _ _
-->Si on utilise le délimiteur ‘virgule’, on obtient _ _ colonnes, et certaines données sont _ _ _ _ _ _ _ _ avec d’autres (donc pas intéressant !) ;
-->Si on utilise le délimiteur ‘espace’, qu’observez-vous ? :
* -->Re-séléctionnez le délimiteur le mieux adapté :
* Certains mots sont mal écrits, on a perdu les _ _ _ _ _
--> Dans le menu déroulant ‘Origine du fichier’, choisir, tout en bas : 65001 unicode (UTF-8) : l’UTF-8 permet de gérer les accents
* Et cliquez sur ‘Charger’.
--> Le tableau se charge. Regardez à droite, combien de ligne de données contient ce tableau ? :
• Que remarquez-vous au niveau de la présentation des descripteurs en ligne 1 ? :
* -->Cliquer sur le triangle du descripteur en colonne 2 nommé : ‘intitulé de gare’, et écrire dans la barre de recherche du menu déroulant qui s’affiche : « Reims »-->Entrée ; Qu’observez-vous ? :
* --> Cliquer sur l’entonnoir du même descripteur, et dans le menu déroulant, cliquer sur ‘effacer le filtre’ ;
--> Déplacez le tableau en colonne 15, et demandez les données correspondant au département de la Marne (51) : vous observez _ _ gares trouvées. (chiffre vu en bas à gauche de votre écran)
• Sans revenir en arrière, passez en colonne 22, cliquez sur le triangle du descripteur ‘niveau de service’ et décochez le chiffre 1, puis faîtes ‘ok’ ; qu’observez-vous ? :
-->Ainsi, avec Excel, on peut croiser des requêtes sur des données en agissant sur le tri des descripteurs.
Cherchez ce qu’est une requête.
Fermez Excel (pas besoin d’enregistrer).
Avec Python, nous allons pouvoir travailler les Données plus librement.
--> Récupérez le fichier Juyter nommé ‘4_2_1 CSV_Jupyter.ipynb’, et placez le dans un dossier (par exemple : SNT/Donnees) ;
--> Récupérez le fichier nommé ‘villes_virgule.csv’, et placez le dans le même dossier pour que le programme le trouve ;
--> Dans un premier temps, faîtes un clic-droit sur le fichier nommé ‘villes_virgule.csv’, et choisissez ‘Ouvrir avec’, puis choisissez l’application Word (ne pas cocher la case : toujours avec cette application !) ;
--> Faîtes en sorte que le fichier s’ouvre en Unicode (UTF-8)
* Quel est le délimiteur de données ? :
* Le nombre de page est de : _ _ _ ; le nombre de mots est de : _ _ _ _ _ ;
--> C’est bien de la Data (Fermez Word sans enregistrer)
--> Ouvrir EduPython, puis le serveur Jupyter en prenant SNT/Donnees comme répertoire de base
--> Ouvrez alors, dans Jupyter, le fichier ‘4_2_1 CSV_Jupyter.ipynb’;
--> Commençons par étudier la 1ère cellule de code nommée ‘Script 1’ :
--> Dans ce programme, quelle est la commande pour :
• récupérer le module ‘pandas’ : _ _ _ _
• lire un fichier de format .csv : _ _ _ _ _
--> Dans quelle variable le contenu du fichier csv est placé ? : _ _ _ _
--> Quelle est la commande pour visualiser le contenu d’une variable : _ _ _ _
--> A présent, lançons le script 1 (barre bleue à gauche du code !) : cliquez sur Exécuter (bouton Play :45sec. d’attente..) ;
-->Combien de lignes et de colonnes contient ce tableau de données ? :
--> Dans le tableau affiché sous le script1, qu’observez-vous ? :
--> Lorsqu’il y a trop de données à afficher, Python crée des raccourcis pour ne pas encombrer la cellule de résultats.
* Exécutez le script nommé ‘Script 2’ : Qu’observez-vous comme résultats ? :
* Qu’en déduisez-vous ? :
--> Exécutez à présent le script nommé ‘Script 3’ ;
* Ecrire ‘paris’, puis ‘Paris’ ; qu’observez-vous ? :
* A présent, demandez une ville de votre choix ;
J’ai choisi la ville de : _ _ _ _ _ _ _ ; surface = _ _ _ km² ; Altitude_max=_ _ _ mètres.
* Faîtes ‘ q ‘ pour quitter.
--> Exécutez à présent le script nommé ‘Script 4’ permettant de réaliser une requête sur l’altitude :
* Ecrire l’altitude 1600 -->Entrée ; J’observe _ _ _ villes ayant cette altitude minimale.
* Copiez la ville qui a l’altitude la plus élevée ; Stoppez le script 4 (écrire 0 -->Entrée), remettez à zéro les cellules (dans la barre de menu) (Kernel-->Restart & clear Output-->Restart & clear all outputs), puis Exécutez (Bouton Play) le script 3 en collant (Ctrl V) la ville la plus élevée :
--> Donnez son code postal : _ _ _
--> Son nombre d’habitant en 2012 : __ _ _ _
--> Sa surface : _ _ _ _
Ainsi, Python et son module pandas sont parfaitement adapté pour analyser des données.
2) Les données : Le Cloud : Pourquoi, comment ?
Lundi 8 Juin
--> à rendre avant Lundi 15 Juin
Lundi 8 Juin
--> à rendre avant Lundi 15 Juin

Bonjour à tous,
Aujourd'hui, tous le cours et le DM sont sur le Cloud ;
Cliquez ici pour y accéder.
Votre mission : Réalisez les questions sur les vidéos ; Puis, associez-vous à un de vos camarades (ou plusieurs) de votre classe de SNT pour réaliser les activités de travail collaboratif sur les clouds. Le DM est à rendre avant le 15 juin.
Aujourd'hui, tous le cours et le DM sont sur le Cloud ;
Cliquez ici pour y accéder.
Votre mission : Réalisez les questions sur les vidéos ; Puis, associez-vous à un de vos camarades (ou plusieurs) de votre classe de SNT pour réaliser les activités de travail collaboratif sur les clouds. Le DM est à rendre avant le 15 juin.
2) Les données : Le Big Data et l'écologie
Lundi 15 Juin
--> à rendre avant Lundi 22 Juin
Lundi 15 Juin
--> à rendre avant Lundi 22 Juin

Bonjour à tous,
Le DM d'aujourd'hui est sur mon Cloud ;
Cliquez ici pour y accéder.
Votre mission : Réalisez les questions sur les vidéos. Le DM est à rendre avant le 22 juin.
Le DM d'aujourd'hui est sur mon Cloud ;
Cliquez ici pour y accéder.
Votre mission : Réalisez les questions sur les vidéos. Le DM est à rendre avant le 22 juin.
Nouveau Thème :
La photographie numérique
Lundi 22 Juin
--> à rendre avant Lundi 29 Juin
La photographie numérique
Lundi 22 Juin
--> à rendre avant Lundi 29 Juin
A l’ère du numérique, la photographie s’offre à tout le monde avec de nouveaux usages (selfie, filtre Instagram…) ; pour autant, le principe général de la photographie n’a pas changé mais les évolutions techniques offrent de nouvelles possibilités :
I. Principe de fonctionnement d’un appareil photographique :
• Visionnez la vidéo « Du sténopé à la photographie » :
I. Principe de fonctionnement d’un appareil photographique :
• Visionnez la vidéo « Du sténopé à la photographie » :
Sur une feuille, reprends juste le N° de question I.1) I.2).. et donnes tes réponses :
1) 30Sec. : que veut dire ‘Camera obscura’ et depuis quand est-elle connue ? :
2) 50Sec. : Comment s’appelle le petit trou percé pour laisser passer la lumière ? :
3) 1min15Sec. : Quelle est la caractéristique particulière de l’image obtenue dans la camera obscura ? :
4) 1min25Sec. : par quoi est ensuite remplacé le sténopé pour obtenir une meilleure image ? :
5) 1min45Sec. : Comment l’image est-elle inversée? :
6) 2min20Sec. : Quand se déroule la naissance de la photographie par Nicephore Niepce ? :
7) 2min30Sec. : Qu’est-ce qui est sensible à la lumière sur la plaque ? :
II. Notions de pixel et de couches de couleurs :
• Lisez les questions suivantes, puis visionnez la vidéo « Pixel et couches de couleurs »
1) 30Sec. : que veut dire ‘Camera obscura’ et depuis quand est-elle connue ? :
2) 50Sec. : Comment s’appelle le petit trou percé pour laisser passer la lumière ? :
3) 1min15Sec. : Quelle est la caractéristique particulière de l’image obtenue dans la camera obscura ? :
4) 1min25Sec. : par quoi est ensuite remplacé le sténopé pour obtenir une meilleure image ? :
5) 1min45Sec. : Comment l’image est-elle inversée? :
6) 2min20Sec. : Quand se déroule la naissance de la photographie par Nicephore Niepce ? :
7) 2min30Sec. : Qu’est-ce qui est sensible à la lumière sur la plaque ? :
II. Notions de pixel et de couches de couleurs :
• Lisez les questions suivantes, puis visionnez la vidéo « Pixel et couches de couleurs »
Sur une feuille, reprends juste le N° de question II.1) II.2).. et donnes tes réponses :
1) 10Sec. : De quoi est constitué une image matricielle ? :
2) 40Sec. : Les images de Profondeur 1 Bits peuvent afficher combien de couleurs et lesquelles ? :
3) 45Sec. : Les images de Profondeur 8 Bits peuvent afficher combien de couleurs et lesquelles ? :
4) 1 min.. : Les images RVB présentent combien de couches de couleurs, et lesquelles ? :
5) 1 min05sec.. : Chaque couche peut contenir combien de valeur de couleurs ? :
6) 1 min12sec.. : Combien de couleurs peut générer au total le système RVB ? :
1) 10Sec. : De quoi est constitué une image matricielle ? :
2) 40Sec. : Les images de Profondeur 1 Bits peuvent afficher combien de couleurs et lesquelles ? :
3) 45Sec. : Les images de Profondeur 8 Bits peuvent afficher combien de couleurs et lesquelles ? :
4) 1 min.. : Les images RVB présentent combien de couches de couleurs, et lesquelles ? :
5) 1 min05sec.. : Chaque couche peut contenir combien de valeur de couleurs ? :
6) 1 min12sec.. : Combien de couleurs peut générer au total le système RVB ? :
III. Pixels, couches de couleurs : applications Paint, Python et Glitch :
Sur une feuille, reprends juste le N° de question III.1) III.2).. et donnes tes réponses :
• Créez un dossier « Analyse_image » et placez dedans un nouveau dossier nommé « images » , ainsi que le script « pixel.ipynb » :
• Ouvrir Paint (Dans la barre de recherche de Windows, tapez « paint » puis Entrée) ;
• En haut à gauche, cliquez sur Fichier-->Nouveau ;
• Dans le menu Accueil, sous-menu Image, cliquez sur l’icône « Redimensionner » .
• Cliquez sur Pixels, décochez « conserver les proportions », et inscrire 10 et 10 dans Horizontal et vertical ; Cliquez sur « OK »
--> En bas à droite de l’écran Paint, mettre le zoom à 800%,
• 1) Qu’observez-vous ? :
• Dans le menu Accueil, sous-menu Outils, choisir Crayon.
* Sélectionner la couleur noire et la taille la plus petite (comme ci-contre) :
Sur une feuille, reprends juste le N° de question III.1) III.2).. et donnes tes réponses :
• Créez un dossier « Analyse_image » et placez dedans un nouveau dossier nommé « images » , ainsi que le script « pixel.ipynb » :
• Ouvrir Paint (Dans la barre de recherche de Windows, tapez « paint » puis Entrée) ;
• En haut à gauche, cliquez sur Fichier-->Nouveau ;
• Dans le menu Accueil, sous-menu Image, cliquez sur l’icône « Redimensionner » .
• Cliquez sur Pixels, décochez « conserver les proportions », et inscrire 10 et 10 dans Horizontal et vertical ; Cliquez sur « OK »
--> En bas à droite de l’écran Paint, mettre le zoom à 800%,
• 1) Qu’observez-vous ? :
• Dans le menu Accueil, sous-menu Outils, choisir Crayon.
* Sélectionner la couleur noire et la taille la plus petite (comme ci-contre) :
--> Réalisez avec ce crayon une bordure en damier comme ci-dessous :

• 2) Comment nomme-t-on les carrés noirs que vous venez de dessiner ? :
• Sauvegardez votre travail « damier » en .png, dans le dossier « images » que vous avez créés précédemment.
* Ouvrez Edupython, et lancez Jupyter Notebook. Déplacez-vous dans le dossier « Analyse_image » que vous venez de créer ;
* Ouvrez le fichier Python nommé « Pixel.ipynb »
• Cliquez sur Exécuter pour lancer le script ;
* Dans le menu qui apparaît, tapez 1 : Lecture-affichage d'une photo ;
--> Le deuxième menu qui apparaît doit vous présenter comme choix l’image que vous venez juste de créer : « damier.png ».
• Inscrire le N° de cette image et faîtes Entrée.
• Regardez bien, c'est tout petit (pixels) en bas à gauche de l'écran Jupyter !
* 3) Qu’observez-vous ? :
* Tapez Entrée, puis dans le menu, tapez 1 pour obtenir les paramètres de l’image :
* Nous avons réalisé une image (10x10) pixels ;
* 4) Combien de colonnes et de lignes possède le tableau de valeurs codant l’image ? :
--> Dès lors, pourquoi la 1ère colonne et la 1ère ligne se nomment 0 ? Ok, inscrire 0 à la question : ‘Choisissez un N° de colonnes :
• Etudiez bien les valeurs RGB de la colonne N°0 de pixels ;
* 5) Qu’observez-vous ? :
• A présent, retournez sur Paint, et complétez votre damier comme sur la figure ci-contre, avec des couleurs : rouge, orange, jaune et vert en 3x3, 5x5, 7x7, 9x9 ;
• Sauvegardez votre travail « damier » en .png, dans le dossier « images » que vous avez créés précédemment.
* Ouvrez Edupython, et lancez Jupyter Notebook. Déplacez-vous dans le dossier « Analyse_image » que vous venez de créer ;
* Ouvrez le fichier Python nommé « Pixel.ipynb »
• Cliquez sur Exécuter pour lancer le script ;
* Dans le menu qui apparaît, tapez 1 : Lecture-affichage d'une photo ;
--> Le deuxième menu qui apparaît doit vous présenter comme choix l’image que vous venez juste de créer : « damier.png ».
• Inscrire le N° de cette image et faîtes Entrée.
• Regardez bien, c'est tout petit (pixels) en bas à gauche de l'écran Jupyter !
* 3) Qu’observez-vous ? :
* Tapez Entrée, puis dans le menu, tapez 1 pour obtenir les paramètres de l’image :
* Nous avons réalisé une image (10x10) pixels ;
* 4) Combien de colonnes et de lignes possède le tableau de valeurs codant l’image ? :
--> Dès lors, pourquoi la 1ère colonne et la 1ère ligne se nomment 0 ? Ok, inscrire 0 à la question : ‘Choisissez un N° de colonnes :
• Etudiez bien les valeurs RGB de la colonne N°0 de pixels ;
* 5) Qu’observez-vous ? :
• A présent, retournez sur Paint, et complétez votre damier comme sur la figure ci-contre, avec des couleurs : rouge, orange, jaune et vert en 3x3, 5x5, 7x7, 9x9 ;

* Et sauvegardez-le sous le nom : « damier_couleur.png » ;
• Retournez sur Jupyter Notebook, et faîtes Q pour revenir au menu ;
• Faîtes 1 pour demander l’affichage d’une image, puis donnez le N° de la photo « damier_couleur » ;
* Faîtes Entrée, puis 1 pour obtenir les paramètres ;
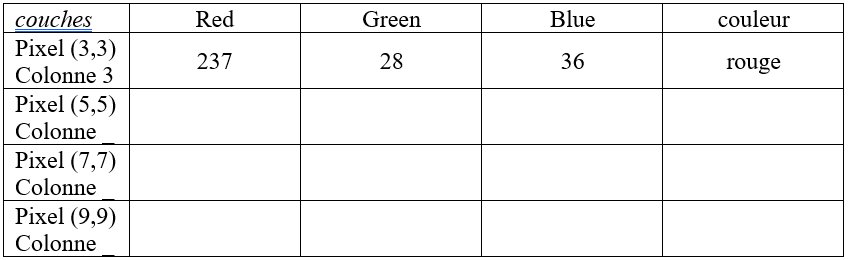
* Vous allez noter, ci-dessous, les 3 valeurs numériques des pixels colorés observés dans cette image en donnant le bon N° de colonne de pixels, notez aussi la couleur des pixels :
* 6) : Refaîtes ce tableau complété :
• Retournez sur Jupyter Notebook, et faîtes Q pour revenir au menu ;
• Faîtes 1 pour demander l’affichage d’une image, puis donnez le N° de la photo « damier_couleur » ;
* Faîtes Entrée, puis 1 pour obtenir les paramètres ;
* Vous allez noter, ci-dessous, les 3 valeurs numériques des pixels colorés observés dans cette image en donnant le bon N° de colonne de pixels, notez aussi la couleur des pixels :
* 6) : Refaîtes ce tableau complété :
• A présent, ouvrez un navigateur et allez à l’adresse suivante :
http://www.proftnj.com/RGB3.htm
• Pour chacun de vos pixels colorés, remplissez sur cette page web les 3 valeurs Red Green Blue (dans la colonne ‘Decimal RGB’) et cliquez sur ‘Montrer’ juste en dessous :
* 7) Qu’observez-vous ? Que conclure ? :
* Ecrivez, à nouveau, les 3 valeurs RVB pour la couleur rouge (cf. tableau ci-dessus), et récupérez son codage hexadécimal :
8) code HEX # :
--> Voyons comment fonctionne la conversion Décimal --> Hexadécimal :
• Pour le rouge, la valeur R = 237 : c’est une valeur décimale
* Vous devez diviser chaque valeur décimale par 16 :
--> 237/16 = 14,### : 14 virgule quelque chose
• Voici la table de conversion :
http://www.proftnj.com/RGB3.htm
• Pour chacun de vos pixels colorés, remplissez sur cette page web les 3 valeurs Red Green Blue (dans la colonne ‘Decimal RGB’) et cliquez sur ‘Montrer’ juste en dessous :
* 7) Qu’observez-vous ? Que conclure ? :
* Ecrivez, à nouveau, les 3 valeurs RVB pour la couleur rouge (cf. tableau ci-dessus), et récupérez son codage hexadécimal :
8) code HEX # :
--> Voyons comment fonctionne la conversion Décimal --> Hexadécimal :
• Pour le rouge, la valeur R = 237 : c’est une valeur décimale
* Vous devez diviser chaque valeur décimale par 16 :
--> 237/16 = 14,### : 14 virgule quelque chose
• Voici la table de conversion :

* Donc, ce 14 en décimal devient E ;
--> Oui , mais 14x16=224 … qui n’est pas égal à 237 : il reste 13
• Il nous faut coder 13..
* D’après le tableau de conversion, 9) 13 est codé en :
• 10) C’est pourquoi notre valeur 237 est codée en hexadécimal par :
* Comme vous pouvez le remarquer, ces deux premiers caractères sont les deux 1ers caractères du code hexadécimal à 6 caractères caractérisant notre rouge !!… (voir plus haut)
--> Rendez -vous à la page Web suivante :
https://glitch.com/
• Nous sommes déjà venus sur ce site, glitch, qui permet de coder du HTML, CSS, et d’observer directement le visuel Web ;
* Cliquez sur ‘Créez un nouveau projet’, puis sur « Hello Web Page »…
--> Dans la marge de gauche, cliquez un coup sur ‘style.css’
• Observez la ligne du code CSS où est écrit ‘color’ ;
11) Que peut ont changer ? :
* Faîtes-le ;
12) Qu’observe-t-on ? :
--> Oui , mais 14x16=224 … qui n’est pas égal à 237 : il reste 13
• Il nous faut coder 13..
* D’après le tableau de conversion, 9) 13 est codé en :
• 10) C’est pourquoi notre valeur 237 est codée en hexadécimal par :
* Comme vous pouvez le remarquer, ces deux premiers caractères sont les deux 1ers caractères du code hexadécimal à 6 caractères caractérisant notre rouge !!… (voir plus haut)
--> Rendez -vous à la page Web suivante :
https://glitch.com/
• Nous sommes déjà venus sur ce site, glitch, qui permet de coder du HTML, CSS, et d’observer directement le visuel Web ;
* Cliquez sur ‘Créez un nouveau projet’, puis sur « Hello Web Page »…
--> Dans la marge de gauche, cliquez un coup sur ‘style.css’
• Observez la ligne du code CSS où est écrit ‘color’ ;
11) Que peut ont changer ? :
* Faîtes-le ;
12) Qu’observe-t-on ? :

